Siggraph 2018: The Road toward Unified Rendering with Unity’s High Definition Render Pipeline
September 3, 2018 1 Comment
The slides of my and Evgenii Golubev talk “The Road toward Unified Rendering with Unity’s High Definition Render Pipeline” in the advance realtime rendering course at Siggraph 2018 are available here:
http://advances.realtimerendering.com/s2018/index.htm
This talk is about the architecture of Unity’s High Definition Render Pipeline (HDRP – Lighting, Material, Decal) from a high level perspective and it provide some implementation details about our BRDF and volumetric lighting algorithm.
The initial goal of this talk was to share as much as possible the new stuff that we have develop for HDRP. It appear that there was really too much to say and too little time. I have already added several slides that was not show during the Siggraph presentation (Which explain a bit why some transition are not smooth :)), but initially there was way more. Will need to do more talk about it to cover them, but will try to go more in depth next time.
I will try during the next few month to provide more implementation details on my blog as slides format don’t allow to be as verbose as course notes. I started with a short blog post about GBuffer packing function. Given that all the source code of HDRP is available here: https://github.com/Unity-Technologies/ScriptableRenderPipeline I feel a bit less guilty of only having scratching the surface of some concept like surface gradient framework (That I highly recommend to adopt) – Also for this one it is Morten Mikklesen that should write a blog post about it!
In this talk, I was willing to discuss the lighting, material and decals architecture from high level perspective to highlight that when we try to do thing “correctly” and within performance constrain, there is not so much flexibility left. I like the example of deferred decal as this is a topic I often heard about. Why do you not support deferred decal, they are so performant ?
Having decal working correctly with material for baked GI is currently not easy and solution like deferred decal are full of mess (in addition to be a nightmare for blend state combination) and they don’t work in forward rendering.
I also was willing to promote an architecture that support features parity between forward and deferred path. Showing what are the technical constrain and how this is convenient for performance comparison (When you are a generalist engine).
Once thing I haven’t discuss in the talk and will do here is the limitation of the “correctness” of screen space reflection (SSR). Artists always ask this feature whatever the engine they work on.
SSR is part of the reflection hierarchy (SSR, planar reflection, reflection probe, sky) and is very helpful to perform specular occlusion at the same time. It is often implemented as a gaussian blur (trying to mimic GGX) with parameter normal, roughness and F0 that are store in a Buffer (usually 2 render target of the GBuffer).
For performance reasons this pass is always done separately from the main lighting loop and often in async compute. This mean that the only available parameters are those output in the buffer. And this is where thing get messy.
The benefit of forward is to allow to implement complex BRDF, like anisotropic layered material. But then, the multiple normal and multiple roughness don’t fit inside the buffer use for SSR! What does it mean in practice?
This mean that inside the reflection hierarchy, wherever you have SSR (i.e in several location of the screen), your nice lighting model like coating simply disappear as it is replace by some kind of gaussian BRDF. There is not really alternative here. We could perform the SSR pass inside the light loop itself. In this case correct implementation could be perform with using multiple raymarching for different normal etc… But this is obviously impractical from performance point of view.
So SSR is nice, as long as the lighting model match the simple Gaussian model that it try to mimic. We hit here the limitation of screen space method and our only salvation will be real time raytracing as already highlight by many 🙂
Errata in the presentation:
- Slide 33: “Ambient occlusion apply on static lighting during GBuffer pass if no RT5” = > “Ambient occlusion apply on static lighting during GBuffer pass if no RT4”
At the same course there is also the talk of Evgenii Golubev about “Efficient Screen-Space Subsurface Scattering Using Burley’s Normalized Diffusion in Real-Time” which discuss about the Disney SSS method we develop for HDRP.

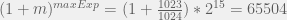 . Whereas 14-bit float format has no leading 1, but a max exponent of 16. Largest value is
. Whereas 14-bit float format has no leading 1, but a max exponent of 16. Largest value is 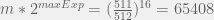 . 10-bit and 11-bit float format follow same rules as 16-bit float format.
. 10-bit and 11-bit float format follow same rules as 16-bit float format.